From:http://eservice.seed.net.tw/class/class0801c.html多重通訊協定標籤交換傳輸(Multi-Protocol Label Switching)是由IETF 所發展出來的Network Standard。它是實現寬頻網際網路最熱門的技術;其目的是要提供一個更具彈性、擴充性及效率更高的IP層交換技術。 |
傳統IP Network 的運作方式Packet在一般的IP Network傳遞時,路由器的運作是以所謂的"Store and Forward"的程序來做Packet路由的選擇及轉送,所以當路由器收到一個Packet時,會先儲存Packet 、分析路由、轉送Packet 到下一個適當的路由器,而當此路由器又收到下一個Packet 要傳送到相同的目的地時,它必須重覆執行相同的程序(儲存、分析、轉送),這樣是很沒有效率的而且會耗用路由器大量的CPU處理能力及記憶體空間,此外傳統的路由器是以軟體的處理方式轉送IP 封包,而MPLS的技術則是引用與ATM交換技術類似的標籤交換(Label Switching)技術,簡化了路由器的轉送功能直接利用Switching Fabric以線上速度(Line Speed)來轉送封包(Packet)到達目的地。 |
MPLS Label 的Format及插入Packet的位置Label是一個4Bytes、固定長度、locally-significant identifier類似在ATM網路中VPI(Virtual Path Identifier)/VCI(Virtual Circuit Identifier)或是Frame-Relay網路中的DLCI(Data Link Circuit Identifier),Label是被插入於Packet的第二層資料鏈結層(data link layer)與第三層網路層(network layer)Header之間。 |
 |
MPLS Network 的組成MPLS 網路是由多個具有標籤交換能力的路由器LSR(Label Switch Router)互相連結所組成,根據在MPLS網路內扮演角色的不同LSR可以分為三種類型: |
 |
Label Assignment and Distribution的過程
|
 |
 |
 |
 |
 |
Packet在MPLS網路中傳送的過程
|
 |
在MPLS網路中Egress LSR double lookup的問題由於Egress LSR不但要查看LFIB中的資料以便移除Packet 中的Label,而且還要查看FIB中的資料以決定將Packet往IP網路的下一個節點傳送,這樣的作法會使Egress LSR 的負擔太重,而且對傳送有Label的封包也不是最有效的方式。 |
 |
Penultimate Hop Popping所以解決的方式就是在原來Egress LSR前一個節點就把Label移除,最後一顆Router 只要做IP lookup 就好了,此種運作方式稱為Penultimate Hop Popping。 |
 |
結語本篇文章從一開始介紹傳統路由器在IP 路由傳送封包的運作缺點及描述發展MPLS技術的優勢,並且說明整個MPLS 技術的運作原理,從MPLS Label的format介紹及Label在封包標頭位置的解說,到整個MPLS網路中各個不同角色LSR的運作方式,在其中更詳細的探討Label 如何被Assignment及 相鄰LSR之間如何交換彼此的Label Information的過程,另外更舉例說明封包在MPLS網路中從Push(加上)Label,一直到離開MPLS網路前Pop(去除)Label的詳細過程,最後則探討為何封包在離開MPLS網路的前一個節點(Hop)就要先Pop(去除)Label的原因。 |
2018年12月27日 星期四
什麼是MPLS
2018年9月20日 星期四
用ipset配置linux防火牆
From:http://blog.chinaunix.net/uid-21706718-id-3561951.html
iptables是在linux內核裡配置防火牆規則的用戶空間工具,它實際上是netfilter框架的一部分.可能因為iptables是netfilter框架裡最常見的部分,所以這個框架通常被稱為iptables,iptables是linux從2.4版本引入的防火牆解決方案.
ipset是iptables的擴展,它允許你創建匹配整個地址sets(地址集合)的規則。而不像普通的iptables鍊是線性的存儲和過濾,ip集合存儲在帶索引的數據結構中,這種結構即時集合比較大也可以進行高效的查找.
除了一些常用的情況,比如阻止一些危險主機訪問本機,從而減少系統資源佔用或網絡擁塞,IPsets也具備一些新防火牆設計方法,並簡化了配置.
在本文中,在快速的討論ipsets的安裝要求後,我會花一點時間來介紹iptables的核心機制和基本概念.然後我會介紹ipset的使用方法和語法,並且演示ipset如何與iptables結合來完成各種不同的配置。最後,我會提供一些細節和較高級的例子來演示如何解決現實中的問題。
ipset比傳統的iptables擁有顯著的性能提升和擴展特性,比如將單個防火牆規則通過一次配置應用到整個主機所在的組和網絡。
由於ipset只是iptables的擴展,所以也會對iptables進行描述。
在許多的linux發布中ipset是一個簡單的安裝包,大家可以通過自己的linux發行版提供的包管理工具進行安裝。
需要理解的重點時,同iptables一樣,ipset是由用戶空間的工具和內核空間的模塊兩部分組成,所以你需要將這兩部分都準備好。你也需要"ipset-aware"這個iptables模塊,這個模塊用來增加rules that match against sets。(……)
首先我們使用自己的linux發行版的包管理工具對ipset進行搜索。在ubuntu上安裝需要安裝ipset和xtables-addons-source包,然後,運行module-assistant auto-install xtables-addons,等待大約30秒後ipset就可以使用了。
如果你的linux發行版沒有被支持,那就需要根據ipset首頁中的安裝步驟構建源碼並對內核打補丁。
這篇文章中使用ipset v4.3和iptables v1.4.9。
iptables概述
簡單來講,iptables防火牆配置由規則鏈的集合組成,每一個鏈包含一個規則。一個數據包,在各個處理階段,內核商量合適的規則來決定數據報的命運。
規則鏈按照順序進行匹配,基於數據包的流向(remote-to-local, remote-to-remote or local-to-remote)和當前所處的處理階段(before or after "routing")。參考圖1。

iptables是在linux內核裡配置防火牆規則的用戶空間工具,它實際上是netfilter框架的一部分.可能因為iptables是netfilter框架裡最常見的部分,所以這個框架通常被稱為iptables,iptables是linux從2.4版本引入的防火牆解決方案.
ipset是iptables的擴展,它允許你創建匹配整個地址sets(地址集合)的規則。而不像普通的iptables鍊是線性的存儲和過濾,ip集合存儲在帶索引的數據結構中,這種結構即時集合比較大也可以進行高效的查找.
除了一些常用的情況,比如阻止一些危險主機訪問本機,從而減少系統資源佔用或網絡擁塞,IPsets也具備一些新防火牆設計方法,並簡化了配置.
在本文中,在快速的討論ipsets的安裝要求後,我會花一點時間來介紹iptables的核心機制和基本概念.然後我會介紹ipset的使用方法和語法,並且演示ipset如何與iptables結合來完成各種不同的配置。最後,我會提供一些細節和較高級的例子來演示如何解決現實中的問題。
ipset比傳統的iptables擁有顯著的性能提升和擴展特性,比如將單個防火牆規則通過一次配置應用到整個主機所在的組和網絡。
由於ipset只是iptables的擴展,所以也會對iptables進行描述。
在許多的linux發布中ipset是一個簡單的安裝包,大家可以通過自己的linux發行版提供的包管理工具進行安裝。
需要理解的重點時,同iptables一樣,ipset是由用戶空間的工具和內核空間的模塊兩部分組成,所以你需要將這兩部分都準備好。你也需要"ipset-aware"這個iptables模塊,這個模塊用來增加rules that match against sets。(……)
首先我們使用自己的linux發行版的包管理工具對ipset進行搜索。在ubuntu上安裝需要安裝ipset和xtables-addons-source包,然後,運行module-assistant auto-install xtables-addons,等待大約30秒後ipset就可以使用了。
如果你的linux發行版沒有被支持,那就需要根據ipset首頁中的安裝步驟構建源碼並對內核打補丁。
這篇文章中使用ipset v4.3和iptables v1.4.9。
iptables概述
簡單來講,iptables防火牆配置由規則鏈的集合組成,每一個鏈包含一個規則。一個數據包,在各個處理階段,內核商量合適的規則來決定數據報的命運。
規則鏈按照順序進行匹配,基於數據包的流向(remote-to-local, remote-to-remote or local-to-remote)和當前所處的處理階段(before or after "routing")。參考圖1。
| 當需要匹配規則鏈時,數據包需要與鏈中的每個規則按照順序進行比對,直道找到匹配的規則。一旦找到了匹配的規則,目標規則就會被調用。如果最後一個規則與數據包也不匹配,就會使用默認規則。 一個規則鏈就是許多規則按順序排列組成,一個規則就是match/target的組合。一個簡單的match例子是“TCP目標端口為80”。target的例子是“接受這個包”。target同樣可以將數據包重定向到其他的用戶自定義的鏈,用戶自定義鏈提供了一些機制,包括組合和細分規則,將多個鏈級聯來完成一個功能。 每一個用來定義規則的iptables命令,不管是用於簡單的規則還是複雜的規則,都有三個基本的部分組成,包括指定table/chain (and order), match和target。  Figure 2.解析iptables命令 配置所有的這些選項,創建一個完整得防火牆,你需要按照特定的順序運行一系列的iptables命令。 iptables非常強大並且可擴展。除了許多內部特性,iptables提供了擴展match和target的API。 ipset ipset是iptables的match擴展。如果要使用它,需要使用ipset命令行工具創建一個集合併指定一個唯一的集和名,然後在iptables規則的match部分分別索引這些集合。 一個集合是一個方便有效快速查詢的地址列表。 下面有兩個常見的iptables命令,這兩個命令阻止從1.1.1.1和2.2.2.2進入主機的數據包: iptables -A INPUT -s 1.1.1.1 -j DROP iptables -A INPUT -s 2.2.2.2 -j DROP match部分語法-s 1.1.1.1表示“匹配源地址是1.1.1.1的數據包”。 下面的ipset/iptables命令同樣可以達到上面的目的: ipset -N myset iphash ipset -A myset 1.1.1.1 ipset -A myset 2.2.2.2 iptables -A INPUT -m set --set myset src -j DROP 上面的ipset命令創建了一個包含兩個地址(1.1.1.1 and 2.2.2.2)的集合(myset of type iphash)。 然後iptables命令通過-m set --set myset src這個match選項使用這個集合,這個匹配規則的意思是“匹配源地址包含在集合myset中的數據包” src表示源地址,dst表示目標地址。如果同時使用src和dst表示既要匹配源地址又要匹配目的地址。 在第二個例子裡,只需要一個iptables命令,不管集合裡有多少ip地址需要添加。雖然這個例子裡只使用了兩個地址,但是你可以依據這個例子簡單的定義1000個地址,並且仍然只需要一條iptables語句。而如果使用第一個例子的方法,不使用ipset,就需要1000條iptables規則。 Set Types 每一個集合都是特定類型的,它不但定義了什麼類型的值可以儲存在裡面(IP addresses, networks, ports and so on),而且定義瞭如何匹配數據包(換言之,數據包的那一部分需要被檢查和如何檢查)。除了一些最通用的集合類型,比如檢查ip地址,也提供了一些其他的集合類型,比如檢查端口,地址和端口同時檢查,mac地址和ip地址同時檢查等。 每一種集合類型都有自己的規則,這些規則表示集合的類型,範圍,它包含的值得分佈。不同的集合類型使用不同的類型索引,並且在不同的情況下被優化。需要根據不同的現實情況選擇集合類型。 最靈活的集合類型是iphash,它可以存儲任意的ip地址和nethash(IP/mask)。請參考ipset的man手冊來了解所有的集合類型。 setlist是一個特別的集合類型,它允許組織多個集合到一個集合裡面。比如你需要一個單獨的集合既包含ip地址又包含網絡信息。 Advantages of ipset 除了性能優勢,一些情況下ipset允許更直接的配置方法。 如果你想定義一個防火牆環境,該環境不會處理來自1.1.1.1和2.2.2.2的包,並且處理過程包含在mychain中,注意下面的方法是無效的: iptables -A INPUT -s ! 1.1.1.1 -g mychain iptables -A INPUT -s ! 2.2.2.2 -g mychain 如果數據包來自1.1.1.1,它匹配第一條規則失敗,但是匹配第二條規則時會成功。如果數據包來自2.2.2.2,匹配第一個規則就會成功。 雖然有有一些其它的方法可以不適用ipset就能達到指定的要求,但是ipset是最直接了當的。 ipset -N myset iphash ipset -A myset 1.1.1.1 ipset -A myset 2.2.2.2 iptables -A INPUT -m set ! --set myset src -g mychain 用上面的方法,如果數據包來自1.1.1.1,它不會匹配規則(because the source address 1.1.1.1 does match the set myset)。如果數據包來自2.2.2.2,它也不會匹配規則。 這只是一個簡單的例子,它說明在一個規則裡匹配完整條件的基本優點。其他方面,每個iptables規則與其它規則是獨立的,並且將規則邏輯的連接起來是比較難的,特別當它包含混合了正常和反向測試時。ipset只是在這些情況下使配置變簡單。 ipset的另一個優勢是集合可以動態的修改,即使iptables的規則正在使用這個集合。添加/修改/刪除接口使用很簡單並且是順序無關的。另一方面,在iptables裡每一條規則都比較複雜,並且規則的順序也是很重要的元素,所以修改內部規則很困難並且會存在潛在問題。 |
Excluding WAN, VPN and Other Routed Networks from the NAT—the Right Way
Outbound NAT (SNAT或IP偽裝)允許私有局域網內的主機訪問internet.iptables NAT規則匹配私網內訪問internat的包,並用網關地址替換包的源地址(使數據包看起來像是從網關發送的,從而隱藏網關後面的主機)。
NAT自動跟踪活動的連接,所以它能將返回的包發送給正確的內網主機(通過將數據包的目的地址修改為內部主機地址)。
下面是一個簡單的outbound NAT規則,10.0.0.0/24是內部局域網:
iptables -t nat -A POSTROUTING \
-s 10.0.0.0/24 -j MASQUERADE
該規則匹配所有來自內網的包,並對他們進行偽裝。如果只有一個路由連接到internat這種方法是非常有效率的,通過該路有的所有流量都是公網的流量。然而,如果有連接到其它私有網絡的路由存在,比如VPN或無力WAN連接,你可能就不會使用地址偽裝。
克服這個限制的一個簡單方法是基於物理接口建立NAT規則,而不是使用基於網絡地址的方式。
iptables -t nat -A POSTROUTING \
-o eth0 -j MASQUERADE
該規則假設eth0是外部接口,該規則會匹配所有離開這個接口的包。與前面的規則不同的是,其他內網的數據包通過其它接口訪問公網時不會匹配這條規則(比如OpenVPN的連接)。
雖然許多連接是通過不同的接口路由,但並不能假設所有的鏈接都是這樣。一個例子是基於KAME的IPsec VPN連接(比如Openswan)就不是使用虛擬接口。
不適用上面的接口匹配技術的另一種情況是如果向外的接口(連接到Internet的接口)連接路由到其他私有網絡的中間網絡,而不是連接到Internet。
通過匹配物理接口來設計的防火牆規則可以使用在一些人為限制方面,並且依賴網絡拓撲。
後來發現,ipset還有另一個應用。假設有一個本地LAN (10.0.0.0/24)需要連接到internet,除此之外還有三個本地網絡(10.30.30.0/24, 10.40.40.0/24, 192.168.4.0/23和172.22.0.0/22 ),執行下面的命令:
ipset -N routed_nets nethash
ipset -A routed_nets 10.30.30.0/24
ipset -A routed_nets 10.40.40.0/24
ipset -A routed_nets 192.168.4.0/23
ipset -A routed_nets 172.22.0.0/22
iptables - t nat -A POSTROUTING \
-s 10.0.0.0/24 \
-m set ! --set routed_nets dst \
-j MASQUERADE
如我們所見,ipset簡單的實現了精確匹配。該規則偽裝所有來自(10.0.0.0/24)的數據包,而不處理其他在routed_nets集合中的網絡的包。由於該配置完全基於網絡地址,所以你完全不用擔心其他特殊的網絡連接(比如VPN),也不用擔心物理接口和網絡拓撲。
Limiting Certain PCs to Have Access Only to Certain Public Hosts
假設老闆較關心員工上班時間上網問題,請你限制員工的PC只能訪問指定的幾個網站,但是不想所有的內部PC都受到限制。
限制3台PC (10.0.0.5, 10.0.0.6 and 10.0.0.7)只能訪問worksite1.com,worksite2.com和worksite3.com。執行下面的命令:
ipset -N limited_hosts iphash
ipset -A limited_hosts 10.0.0.5
ipset -A limited_hosts 10.0.0.6
ipset -A limited_hosts 10.0.0.7
ipset -N allowed_sites iphash
ipset -A allowed_sites worksite1.com
ipset -A allowed_sites worksite2.com
ipset -A allowed_sites worksite3.com
iptables -I FORWARD \
-m set --set limited_hosts src \
-m set ! --set allowed_sites dst \
-j DROP
該例子在一條規則裡使用了兩個集合。如果源地址匹配limited_hosts目的地址不匹配allowed_sites,數據包就被丟棄。
注意該規則被添加到了FORWARD鏈,它不會影響防火牆主機自己的通信。
Blocking Access to Hosts for All but Certain PCs (Inverse Scenario)
假設老闆想阻止員工訪問幾個特定的網站,但是不阻止他自己的PC和他助理的PC。在這個例子裡,我們可以匹配老闆和助理的PC的MAC地址,而不是匹配IP地址。假設他們的MAC是11:11:11:11:11:11和22:22:22:22:22:22,需要組織員工訪問的站點是badsite1.com, badsite2.com和badsite3.com.
這次我們不使用第二個集合匹配MAC地址,而是使用多個iptables命令,利用MARK target標記數據包,而利用後面的規則處理被標記的數據包。
ipset -N blocked_sites iphash
ipset -A blocked_sites badsite1.com
ipset -A blocked_sites badsite2.com
ipset -A blocked_sites badsite3.com
iptables -I FORWARD -m mark --mark 0x187 -j DROP
iptables -I FORWARD \
-m mark --mark 0x187 \
-m mac --mac-source 11:11:11:11:11:11 \
-j MARK --set-mark 0x0
iptables -I FORWARD \
-m mark --mark 0x187 \
-m mac --mac-source 22:22:22:22:22:22 \
-j MARK --set-mark 0x0
iptables - I FORWARD \
-m set --set blocked_sites dst \
-j MARK --set-mark 0x187
上面的例子,由於沒有使用ipset完成所有的匹配工作,所以使用的命令比較多,而且比較複雜。由於用到了多個iptables命令,所以各個命令的順序是非常重要的。
注意這些規則是使用—I (insert)選項而不是使用-A (append)選項。當一個規則被插入,他會被添加的鏈的頂端,而以前的規則自動下移。因為每一格規則都是被插入德,所以實際的有效順序是相反的。
最後一個iptables命令實際在FORWARD鏈的頂端。該規則匹配所有目的地址與blocked_sites集合相匹配的數據包,然後將這些數據標記為0x187.下面的兩個規則匹配來自特定MAC地址並且已經標記為0x187的數據包,然後將他們標記為0。
最後,最後的iptables規則丟棄所有的被標記為0x187的數據包。除了來源是兩個特定MAC地址的數據包,他將會匹配所有的目標地址在blocked_sites集合裡的數據包。
這是解決問題的一種方法。還有一些其他方法,除了使用第二個ipset集合的方法,還可以使用用戶自定義鍊等。
使用第二個ipset集合代替標記的方法是不可能完成上面的要求的,因為ipset沒有machash集合類型,只有集合類型,但是他要求同時匹配IP和MAC,而不是只匹配MAC地址。
警告:在大多數實際環境裡,這個方法可能不可行,應為大部分你需要屏蔽的網站他們的主機都有多個ip地址(比如Facebook, MySpace等等),而且這些ip會頻繁的更換。iptables/ipset的一個限制是主機名只有被解析為單個ip地址時才能使用。
而且,主機名lookup只有在命令執行時發生,所以如果ip地址改變了,防火牆是不會意識到的,而是仍然使用以前的ip地址。基於這個原因,一個完成Web訪問限制的更好的方法是使用HTTP代理,比如Squid。
Automatically Ban Hosts That Attempt to Access Invalid Services
ipset為iptables提供了目標擴展功能,它提供了一種向集合動態添加和刪除目標的機制。不必手動使用ipset命令添加目標,而是在運行時通過iptables自動添加。
比如,如果遠程主機嘗試連接端口25,但是你並沒有運行SMTP服務,我們懷疑對方不懷好意,所以我們在對方還沒有乾什麼壞事前就組織他的其他嘗試,使用下面的規則:
ipset -N banned_hosts iphash
iptables -A INPUT \
-p tcp --dport 25 \
-j SET --add-set banned_hosts src
iptables -A INPUT \
-m set --set banned_hosts src \
-j DROP
如果從端口25接收到數據包,假設來源地址是1.1.1.1,那麼該地址馬上就被添加到banned_hosts集合,和下面的例子等效:
ipset -A banned_hosts 1.1.1.1
所有的1.1.1.1的連接都會被阻塞。
他同樣會阻止其他主機對本設備進行端口掃描,除非他不掃描25號端口。
Clearing the Running Config
如果你想清除ipset和iptables的配置,將防火牆reset,運行下面的命令:
iptables -P INPUT ACCEPT
iptables -P OUTPUT ACCEPT
iptables -P FORWARD ACCEPT
iptables -t filter -F
iptables -t raw -F
iptables -t nat -F
iptables -t mangle -F
ipset -F
ipset -X
如果集合正在被使用,意味著其它的iptables規則正在引用該集合,就不能對集合進行銷毀(ipset - X),所以為了在任何狀態下都完成reset,iptables鏈必須首先清除。
Conclusion
ipset為netfilter/iptables在增加了很多有用的特性和功能,正如本篇文章描述的,ipset不僅提供了新的防火牆配製的可能性,而且他減少了之前只使用iptables來配置防火牆的困難。
任何時候,如果你想將防火牆規則應用到一個組,你應該使用ipset。正如前面的例子,你可以通過將ipset與iptables的其它特性相結合,來完成各種各樣的網絡配置和策略。
下一次你再進行防火牆配置時,考慮使用ipset。我相信你會被他的可用性和靈活性震驚。
Resources
Netfilter/iptables Project Home Page: http://www.netfilter.org
ipset Home Page: http://ipset.netfilter.org
原文地址:http://www.linuxjournal.com/content/advanced-firewall-configurations -ipset?page=0,0
Outbound NAT (SNAT或IP偽裝)允許私有局域網內的主機訪問internet.iptables NAT規則匹配私網內訪問internat的包,並用網關地址替換包的源地址(使數據包看起來像是從網關發送的,從而隱藏網關後面的主機)。
NAT自動跟踪活動的連接,所以它能將返回的包發送給正確的內網主機(通過將數據包的目的地址修改為內部主機地址)。
下面是一個簡單的outbound NAT規則,10.0.0.0/24是內部局域網:
iptables -t nat -A POSTROUTING \
-s 10.0.0.0/24 -j MASQUERADE
該規則匹配所有來自內網的包,並對他們進行偽裝。如果只有一個路由連接到internat這種方法是非常有效率的,通過該路有的所有流量都是公網的流量。然而,如果有連接到其它私有網絡的路由存在,比如VPN或無力WAN連接,你可能就不會使用地址偽裝。
克服這個限制的一個簡單方法是基於物理接口建立NAT規則,而不是使用基於網絡地址的方式。
iptables -t nat -A POSTROUTING \
-o eth0 -j MASQUERADE
該規則假設eth0是外部接口,該規則會匹配所有離開這個接口的包。與前面的規則不同的是,其他內網的數據包通過其它接口訪問公網時不會匹配這條規則(比如OpenVPN的連接)。
雖然許多連接是通過不同的接口路由,但並不能假設所有的鏈接都是這樣。一個例子是基於KAME的IPsec VPN連接(比如Openswan)就不是使用虛擬接口。
不適用上面的接口匹配技術的另一種情況是如果向外的接口(連接到Internet的接口)連接路由到其他私有網絡的中間網絡,而不是連接到Internet。
通過匹配物理接口來設計的防火牆規則可以使用在一些人為限制方面,並且依賴網絡拓撲。
後來發現,ipset還有另一個應用。假設有一個本地LAN (10.0.0.0/24)需要連接到internet,除此之外還有三個本地網絡(10.30.30.0/24, 10.40.40.0/24, 192.168.4.0/23和172.22.0.0/22 ),執行下面的命令:
ipset -N routed_nets nethash
ipset -A routed_nets 10.30.30.0/24
ipset -A routed_nets 10.40.40.0/24
ipset -A routed_nets 192.168.4.0/23
ipset -A routed_nets 172.22.0.0/22
iptables - t nat -A POSTROUTING \
-s 10.0.0.0/24 \
-m set ! --set routed_nets dst \
-j MASQUERADE
如我們所見,ipset簡單的實現了精確匹配。該規則偽裝所有來自(10.0.0.0/24)的數據包,而不處理其他在routed_nets集合中的網絡的包。由於該配置完全基於網絡地址,所以你完全不用擔心其他特殊的網絡連接(比如VPN),也不用擔心物理接口和網絡拓撲。
Limiting Certain PCs to Have Access Only to Certain Public Hosts
假設老闆較關心員工上班時間上網問題,請你限制員工的PC只能訪問指定的幾個網站,但是不想所有的內部PC都受到限制。
限制3台PC (10.0.0.5, 10.0.0.6 and 10.0.0.7)只能訪問worksite1.com,worksite2.com和worksite3.com。執行下面的命令:
ipset -N limited_hosts iphash
ipset -A limited_hosts 10.0.0.5
ipset -A limited_hosts 10.0.0.6
ipset -A limited_hosts 10.0.0.7
ipset -N allowed_sites iphash
ipset -A allowed_sites worksite1.com
ipset -A allowed_sites worksite2.com
ipset -A allowed_sites worksite3.com
iptables -I FORWARD \
-m set --set limited_hosts src \
-m set ! --set allowed_sites dst \
-j DROP
該例子在一條規則裡使用了兩個集合。如果源地址匹配limited_hosts目的地址不匹配allowed_sites,數據包就被丟棄。
注意該規則被添加到了FORWARD鏈,它不會影響防火牆主機自己的通信。
Blocking Access to Hosts for All but Certain PCs (Inverse Scenario)
假設老闆想阻止員工訪問幾個特定的網站,但是不阻止他自己的PC和他助理的PC。在這個例子裡,我們可以匹配老闆和助理的PC的MAC地址,而不是匹配IP地址。假設他們的MAC是11:11:11:11:11:11和22:22:22:22:22:22,需要組織員工訪問的站點是badsite1.com, badsite2.com和badsite3.com.
這次我們不使用第二個集合匹配MAC地址,而是使用多個iptables命令,利用MARK target標記數據包,而利用後面的規則處理被標記的數據包。
ipset -N blocked_sites iphash
ipset -A blocked_sites badsite1.com
ipset -A blocked_sites badsite2.com
ipset -A blocked_sites badsite3.com
iptables -I FORWARD -m mark --mark 0x187 -j DROP
iptables -I FORWARD \
-m mark --mark 0x187 \
-m mac --mac-source 11:11:11:11:11:11 \
-j MARK --set-mark 0x0
iptables -I FORWARD \
-m mark --mark 0x187 \
-m mac --mac-source 22:22:22:22:22:22 \
-j MARK --set-mark 0x0
iptables - I FORWARD \
-m set --set blocked_sites dst \
-j MARK --set-mark 0x187
上面的例子,由於沒有使用ipset完成所有的匹配工作,所以使用的命令比較多,而且比較複雜。由於用到了多個iptables命令,所以各個命令的順序是非常重要的。
注意這些規則是使用—I (insert)選項而不是使用-A (append)選項。當一個規則被插入,他會被添加的鏈的頂端,而以前的規則自動下移。因為每一格規則都是被插入德,所以實際的有效順序是相反的。
最後一個iptables命令實際在FORWARD鏈的頂端。該規則匹配所有目的地址與blocked_sites集合相匹配的數據包,然後將這些數據標記為0x187.下面的兩個規則匹配來自特定MAC地址並且已經標記為0x187的數據包,然後將他們標記為0。
最後,最後的iptables規則丟棄所有的被標記為0x187的數據包。除了來源是兩個特定MAC地址的數據包,他將會匹配所有的目標地址在blocked_sites集合裡的數據包。
這是解決問題的一種方法。還有一些其他方法,除了使用第二個ipset集合的方法,還可以使用用戶自定義鍊等。
使用第二個ipset集合代替標記的方法是不可能完成上面的要求的,因為ipset沒有machash集合類型,只有集合類型,但是他要求同時匹配IP和MAC,而不是只匹配MAC地址。
警告:在大多數實際環境裡,這個方法可能不可行,應為大部分你需要屏蔽的網站他們的主機都有多個ip地址(比如Facebook, MySpace等等),而且這些ip會頻繁的更換。iptables/ipset的一個限制是主機名只有被解析為單個ip地址時才能使用。
而且,主機名lookup只有在命令執行時發生,所以如果ip地址改變了,防火牆是不會意識到的,而是仍然使用以前的ip地址。基於這個原因,一個完成Web訪問限制的更好的方法是使用HTTP代理,比如Squid。
Automatically Ban Hosts That Attempt to Access Invalid Services
ipset為iptables提供了目標擴展功能,它提供了一種向集合動態添加和刪除目標的機制。不必手動使用ipset命令添加目標,而是在運行時通過iptables自動添加。
比如,如果遠程主機嘗試連接端口25,但是你並沒有運行SMTP服務,我們懷疑對方不懷好意,所以我們在對方還沒有乾什麼壞事前就組織他的其他嘗試,使用下面的規則:
ipset -N banned_hosts iphash
iptables -A INPUT \
-p tcp --dport 25 \
-j SET --add-set banned_hosts src
iptables -A INPUT \
-m set --set banned_hosts src \
-j DROP
如果從端口25接收到數據包,假設來源地址是1.1.1.1,那麼該地址馬上就被添加到banned_hosts集合,和下面的例子等效:
ipset -A banned_hosts 1.1.1.1
所有的1.1.1.1的連接都會被阻塞。
他同樣會阻止其他主機對本設備進行端口掃描,除非他不掃描25號端口。
Clearing the Running Config
如果你想清除ipset和iptables的配置,將防火牆reset,運行下面的命令:
iptables -P INPUT ACCEPT
iptables -P OUTPUT ACCEPT
iptables -P FORWARD ACCEPT
iptables -t filter -F
iptables -t raw -F
iptables -t nat -F
iptables -t mangle -F
ipset -F
ipset -X
如果集合正在被使用,意味著其它的iptables規則正在引用該集合,就不能對集合進行銷毀(ipset - X),所以為了在任何狀態下都完成reset,iptables鏈必須首先清除。
Conclusion
ipset為netfilter/iptables在增加了很多有用的特性和功能,正如本篇文章描述的,ipset不僅提供了新的防火牆配製的可能性,而且他減少了之前只使用iptables來配置防火牆的困難。
任何時候,如果你想將防火牆規則應用到一個組,你應該使用ipset。正如前面的例子,你可以通過將ipset與iptables的其它特性相結合,來完成各種各樣的網絡配置和策略。
下一次你再進行防火牆配置時,考慮使用ipset。我相信你會被他的可用性和靈活性震驚。
Resources
Netfilter/iptables Project Home Page: http://www.netfilter.org
ipset Home Page: http://ipset.netfilter.org
原文地址:http://www.linuxjournal.com/content/advanced-firewall-configurations -ipset?page=0,0
2018年9月18日 星期二
openwrt中使用ubus實現進程通信的原理
From:http://blog.csdn.net/jasonchen_gbd/article/details/45627967
ubus為openwrt平台開發中的進程間通信提供了一個通用的框架。它讓進程間通信的實現變得非常簡單,並且ubus具有很強的可移植性,可以很方便的移植到其他linux平台上使用。本文描述了ubus的實現原理和整體框架。
1. ubus的實現框架
ubus實現的基礎是unix socket,即本地socket,它相對於用於網絡通信的inet socket更高效,更具可靠性。unix socket客戶端和服務器的實現方式和網絡socket類似,讀者如果還不太熟悉可查閱相關資料。
我們知道實現一個簡單的unix socket服務器和客戶端需要做如下工作:
我們知道實現一個簡單的unix socket服務器和客戶端需要做如下工作:
- 建立一個socket server端,綁定到一個本地socket文件,並監聽clients的連接。
- 建立一個或多個socket client端,連接server。
- client和server相互發送消息。
- client或server收到對方消息後,針對具體消息進行相應處理。

ubus同樣實現了上述組件,並對socket連接以及消息傳輸和處理進行了封裝:
- 1. ubus提供了一個socket server:ubusd。因此開發者不需要自己實現server端。
- 2. ubus提供了創建socket client端的接口,並且提供了三種現成的客戶端供用戶直接使用:
1) 為shell腳本提供的client端。2) 為lua腳本提供的client接口。3) 為C語言提供的client接口。可見ubus對shell和lua增加了支持,後面會介紹這些客戶端的用法。
- 3. ubus對client和server之間通信的消息格式進行了定義:client和server都必須將消息封裝成json消息格式。
- 4. ubus對client端的消息處理抽像出“對象(object)”和“方法(method)”的概念。一個對像中包含多個方法,client需要向server註冊收到特定json消息時的處理方法。對象和方法都有自己的名字,發送請求方只需在消息中指定要調用的對象和方法的名字即可。
使用ubus時需要引用一些動態庫,主要包括:
- libubus.so:ubus向外部提供的編程接口,例如創建socket,進行監聽和連接,發送消息等接口函數。
- libubox.so:ubus向外部提供的編程接口,例如等待和讀取消息。
- libblobmsg.so,libjson.so:提供了封裝和解析json數據的接口,編程時不需要直接使用libjson.so,而是使用libblobmsg.so提供的更靈活的接口函數。
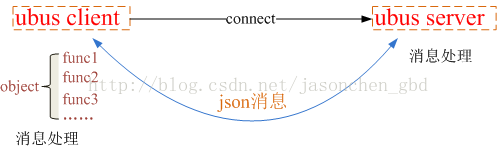
使用ubus進行進程間通信不需要編寫大量代碼,只需按照固定模式調用ubus提供的API即可。在ubus源碼中examples目錄下有一些例子可以參考。
2. ubus的實現原理
下面以一個例子說明ubus的工作原理:下圖中,client2試圖通過ubus修改ip地址,而修改ip地址的函數在client1中定義。
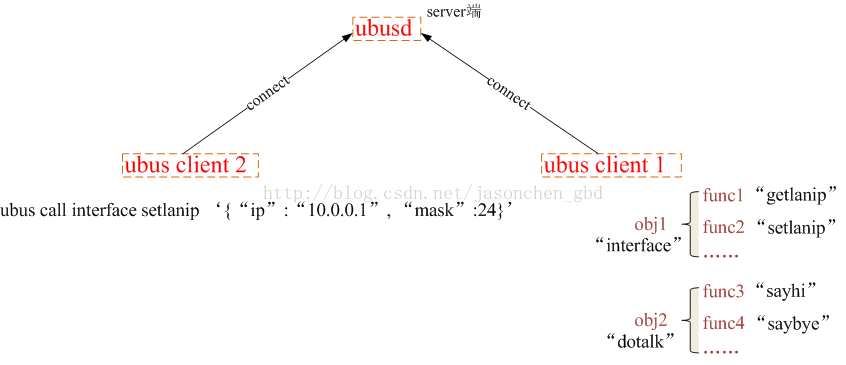
client2進行請求的整個過程為:
1. client1向ubusd註冊了兩個對象:“interface”和“dotalk”,其中“interface”對像中註冊了兩個method:“getlanip”和“setlanip”,對應的處理函數分別為func1()和func2 ()。“dotalk”對像中註冊了兩個method:“sayhi”和“saybye”,對應的處理函數分別為func3()和func4()。2. 接著創建一個client2用來與client1通信,注意,兩個client之間不能直接通信,需要經ubusd(server)中轉。3. client2就是在前面講到的shell/lua/C客戶端。假設這裡使用shell客戶端,在終端輸入以下命令:
ubus的call命令帶三個參數:請求的對象名,需要調用的方法名,要傳給方法的參數。ubus call interface setlanip '{“ip”:“10.0.0.1”, “mask”:24}'
4. 消息發到server後,server根據對象名找到應該將請求轉發給client1,然後將消息發送到client1,client1進而調用func2()接受參數並處理,如果處理完成後需要回复client2,則發送回复消息。
接下來介紹一下上述過程中,ubus內部的處理機制,雖然使用ubus進行進程間通信不需要關注這些實現細節,但有助於加深對ubus實現原理的理解。
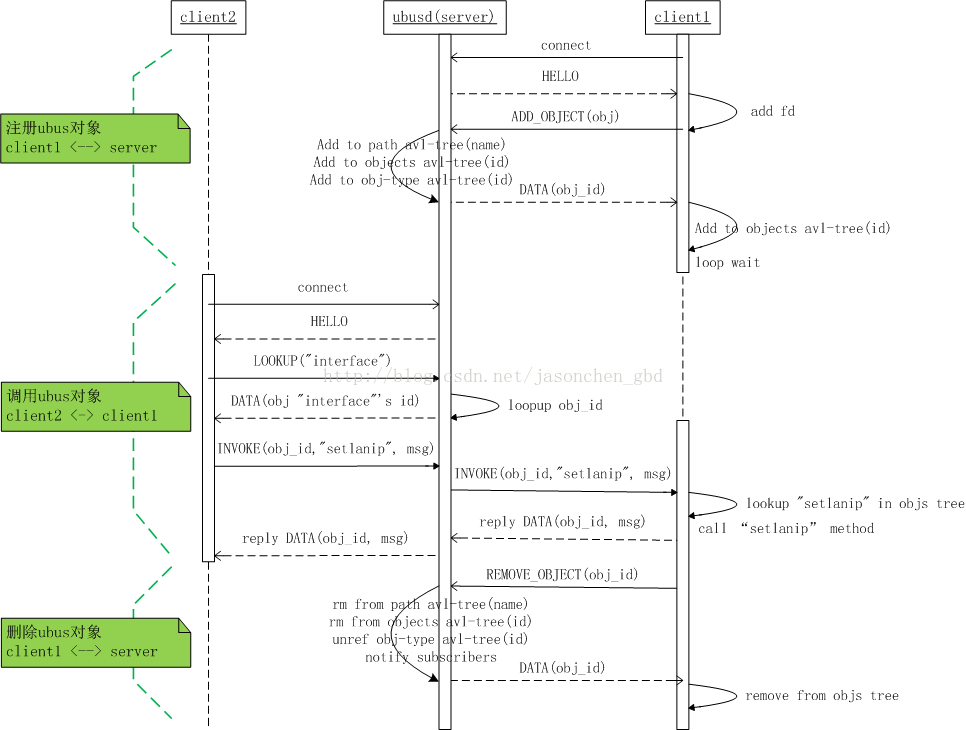
下圖中,client1註冊對象和方法,其實可認為是服務提供端,只不過對於ubusd來講是一個socket client。client2去調用client1註冊的方法。
3. ubus的應用場景和局限性
ubus可用於兩個進程之間的通信,並以類似json格式進行數據交互。ubus的常見場景為:
- “客戶端--服務器”形式的交互,即進程A註冊一系列的服務,進程B去調用這些服務。
- ubus支持以“訂閱-- 通知”的方式進行進程通信,即進程A提供訂閱服務,其他進程可以選擇訂閱或退訂該服務,進程A可以向所有訂閱者發送消息。
由於ubus實現方式的限制,在一些場景中不適宜使用ubus:
- ubus用於少量數據的傳輸,如果數據量很大或是數據交互很頻繁,則不宜用ubus。經過測試,當ubus一次傳輸數據量超過60KB,就不能正常工作了。
- ubus對多線程支持的不好,例如在多個線程中去請求同一個服務,就有可能出現不可預知的結果。
- 不建議遞歸調用ubus,例如進程A去調用進程B的服務,而B的該服務需要調用進程C的服務,之後C將結果返回給B,然後B將結果返回給A。如果不得不這樣做,需要在調用過程中避免全局變量的重用問題。
4. ubus源碼簡析
下面介紹一下ubusd和ubus client工作時的代碼流程,這里為了便於理解,只介紹大致的流程,欲了解詳細的實現請讀者自行閱讀源碼。
4.1 ubusd工作流程
ubusd 的初始化所做的工作如下:
1. epoll_create(32)創建出一個poll_fd。2.創建一個UDP unix socket,並添加到poll_fd的監聽隊列。
3.進行epoll_wait()等待消息。收到消息後的處理函數定義如下:
即調用server_cb()函數。
4. server_cb()函數中的工作為:
(1)進行accept(),接受client連接,並為該連接生成一個client_fd。
(2)為client分配一個client id,用於ubusd區分不同的client。
(3)向client發送一個HELLO消息作為連接建立的標誌。
(4)將client_fd添加到poll_fd的監聽隊列中,用於監聽client發過來的消息,消息處理函數為client_cb()。
也就是說ubusd監聽兩種消息,一種是新client的連接請求,一種是現有的每個client發過來的數據。
當ubusd收到一個client的數據後,調用client_cb()函數的處理過程:
1.先檢查一下是否有需要向這個client回复的數據(可能是上一次請求沒處理完),如果有,先發送這些遺留數據。
2.讀取socket上的數據,根據消息類型(數據中都指定了消息類型的)調用相應的處理函數,消息類型和處理函數定義如下:
例如,如果收到invoke消息,就調用ubusd_handle_invoke()函數處理。
這些處理函數可能是ubusd處理完後需要回發給client數據,或者是將消息轉發給另一個client(如果發送請求的client需要和另一個client進行通信)。
3.處理完成後,向client發送處理結果,例如UBUS_STATUS_OK。(注意,client發送數據是UBUS_MSG_DATA類型的)
4.2 client的工作流程
ubus call obj method的工作流程:
1.創建一個unix socket(UDP)連接ubusd,並接收到server發過來的HELLO消息。2. ubus call命令由ubus_cli_call()函數進行處理,先向ubusd發送lookup消息請求obj的id。然後向ubusd發送invoke消息來調用obj的method方法。
3.創建epoll_fd並將client的fd添加到監聽列表中等待消息。
4. client收到消息後的處理函數為ubus_handle_data(),其中UBUS_MSG_DATA類型的數據receive_call_result_data()函數協助解析。
被call的client的工作流程:
和ubus客戶端的流程相似,只是變成了接受請求並調用處理函數
訂閱:
文章 (Atom)
How to repair and clone disk with ddrescue
ddrescue is a tool that can be used to repair and clone disks on a Linux system . This includes hard drives, partitions, DVD discs, flas...

-
From: http://blog.chinaaet.com/justlxy/p/5100064818 SMI:串行管理接口(Serial Management Interface),通常直接被稱為MDIO接口(Management Data Input/Output I...
-
from: https://www.wpgdadatong.com/tw/blog/detail?BID=B0594 一. PHY包含的各個子層 : PCS:編碼和解碼 PMA:串行器和反序列化器 PMD:取決於物理介質 Firgure 1: OSI模型裡示意...
-
在 前面我們所談的那些可以說是比較基本的東西,但是對於一份文件來說,光有前面所介紹的游標移動、刪除等等功能是不足夠的。面對一份文件我們通常會因為某些 緣故而使得我們必須去修改當中固定出現的字串樣式(pattern)成我們想要的樣子。最常遇到的就像中文文件的標點符號問題,或是 un...


