From:http://blog.csdn.net/jasonchen_gbd/article/details/45627967
ubus為openwrt平台開發中的進程間通信提供了一個通用的框架。它讓進程間通信的實現變得非常簡單,並且ubus具有很強的可移植性,可以很方便的移植到其他linux平台上使用。本文描述了ubus的實現原理和整體框架。
1. ubus的實現框架
ubus實現的基礎是unix socket,即本地socket,它相對於用於網絡通信的inet socket更高效,更具可靠性。unix socket客戶端和服務器的實現方式和網絡socket類似,讀者如果還不太熟悉可查閱相關資料。
我們知道實現一個簡單的unix socket服務器和客戶端需要做如下工作:
我們知道實現一個簡單的unix socket服務器和客戶端需要做如下工作:
- 建立一個socket server端,綁定到一個本地socket文件,並監聽clients的連接。
- 建立一個或多個socket client端,連接server。
- client和server相互發送消息。
- client或server收到對方消息後,針對具體消息進行相應處理。

ubus同樣實現了上述組件,並對socket連接以及消息傳輸和處理進行了封裝:
- 1. ubus提供了一個socket server:ubusd。因此開發者不需要自己實現server端。
- 2. ubus提供了創建socket client端的接口,並且提供了三種現成的客戶端供用戶直接使用:
1) 為shell腳本提供的client端。2) 為lua腳本提供的client接口。3) 為C語言提供的client接口。可見ubus對shell和lua增加了支持,後面會介紹這些客戶端的用法。
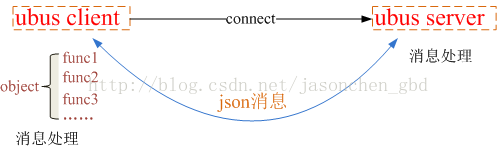
- 3. ubus對client和server之間通信的消息格式進行了定義:client和server都必須將消息封裝成json消息格式。
- 4. ubus對client端的消息處理抽像出“對象(object)”和“方法(method)”的概念。一個對像中包含多個方法,client需要向server註冊收到特定json消息時的處理方法。對象和方法都有自己的名字,發送請求方只需在消息中指定要調用的對象和方法的名字即可。
使用ubus時需要引用一些動態庫,主要包括:
- libubus.so:ubus向外部提供的編程接口,例如創建socket,進行監聽和連接,發送消息等接口函數。
- libubox.so:ubus向外部提供的編程接口,例如等待和讀取消息。
- libblobmsg.so,libjson.so:提供了封裝和解析json數據的接口,編程時不需要直接使用libjson.so,而是使用libblobmsg.so提供的更靈活的接口函數。
使用ubus進行進程間通信不需要編寫大量代碼,只需按照固定模式調用ubus提供的API即可。在ubus源碼中examples目錄下有一些例子可以參考。
2. ubus的實現原理
下面以一個例子說明ubus的工作原理:下圖中,client2試圖通過ubus修改ip地址,而修改ip地址的函數在client1中定義。
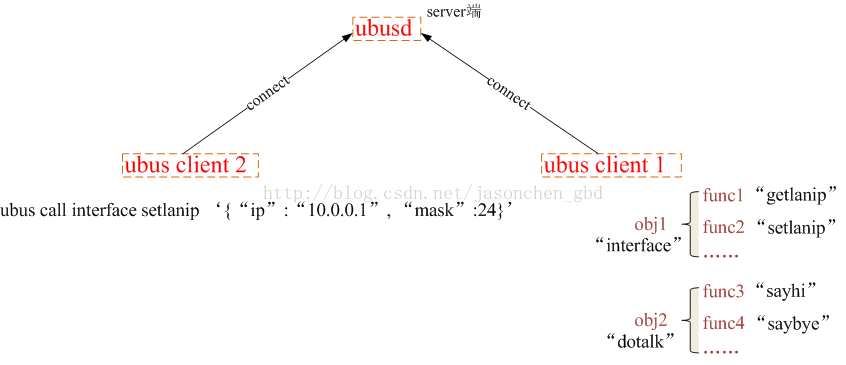
client2進行請求的整個過程為:
1. client1向ubusd註冊了兩個對象:“interface”和“dotalk”,其中“interface”對像中註冊了兩個method:“getlanip”和“setlanip”,對應的處理函數分別為func1()和func2 ()。“dotalk”對像中註冊了兩個method:“sayhi”和“saybye”,對應的處理函數分別為func3()和func4()。2. 接著創建一個client2用來與client1通信,注意,兩個client之間不能直接通信,需要經ubusd(server)中轉。3. client2就是在前面講到的shell/lua/C客戶端。假設這裡使用shell客戶端,在終端輸入以下命令:
ubus的call命令帶三個參數:請求的對象名,需要調用的方法名,要傳給方法的參數。ubus call interface setlanip '{“ip”:“10.0.0.1”, “mask”:24}'
4. 消息發到server後,server根據對象名找到應該將請求轉發給client1,然後將消息發送到client1,client1進而調用func2()接受參數並處理,如果處理完成後需要回复client2,則發送回复消息。
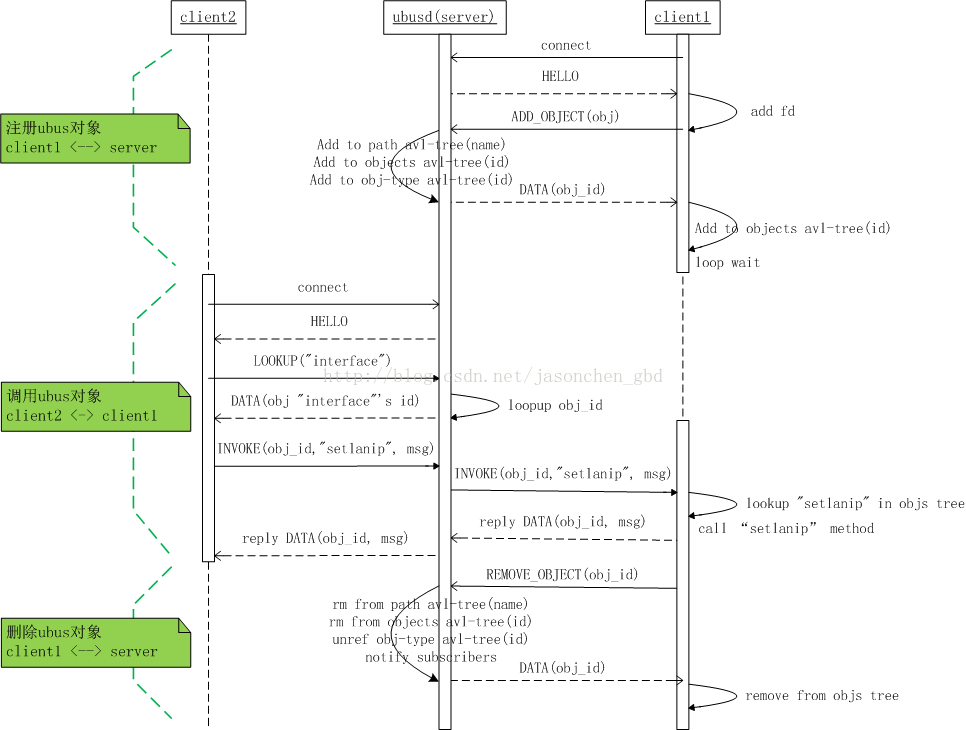
接下來介紹一下上述過程中,ubus內部的處理機制,雖然使用ubus進行進程間通信不需要關注這些實現細節,但有助於加深對ubus實現原理的理解。
下圖中,client1註冊對象和方法,其實可認為是服務提供端,只不過對於ubusd來講是一個socket client。client2去調用client1註冊的方法。
3. ubus的應用場景和局限性
ubus可用於兩個進程之間的通信,並以類似json格式進行數據交互。ubus的常見場景為:
- “客戶端--服務器”形式的交互,即進程A註冊一系列的服務,進程B去調用這些服務。
- ubus支持以“訂閱-- 通知”的方式進行進程通信,即進程A提供訂閱服務,其他進程可以選擇訂閱或退訂該服務,進程A可以向所有訂閱者發送消息。
由於ubus實現方式的限制,在一些場景中不適宜使用ubus:
- ubus用於少量數據的傳輸,如果數據量很大或是數據交互很頻繁,則不宜用ubus。經過測試,當ubus一次傳輸數據量超過60KB,就不能正常工作了。
- ubus對多線程支持的不好,例如在多個線程中去請求同一個服務,就有可能出現不可預知的結果。
- 不建議遞歸調用ubus,例如進程A去調用進程B的服務,而B的該服務需要調用進程C的服務,之後C將結果返回給B,然後B將結果返回給A。如果不得不這樣做,需要在調用過程中避免全局變量的重用問題。
4. ubus源碼簡析
下面介紹一下ubusd和ubus client工作時的代碼流程,這里為了便於理解,只介紹大致的流程,欲了解詳細的實現請讀者自行閱讀源碼。
4.1 ubusd工作流程
ubusd 的初始化所做的工作如下:
1. epoll_create(32)創建出一個poll_fd。2.創建一個UDP unix socket,並添加到poll_fd的監聽隊列。
3.進行epoll_wait()等待消息。收到消息後的處理函數定義如下:
即調用server_cb()函數。
4. server_cb()函數中的工作為:
(1)進行accept(),接受client連接,並為該連接生成一個client_fd。
(2)為client分配一個client id,用於ubusd區分不同的client。
(3)向client發送一個HELLO消息作為連接建立的標誌。
(4)將client_fd添加到poll_fd的監聽隊列中,用於監聽client發過來的消息,消息處理函數為client_cb()。
也就是說ubusd監聽兩種消息,一種是新client的連接請求,一種是現有的每個client發過來的數據。
當ubusd收到一個client的數據後,調用client_cb()函數的處理過程:
1.先檢查一下是否有需要向這個client回复的數據(可能是上一次請求沒處理完),如果有,先發送這些遺留數據。
2.讀取socket上的數據,根據消息類型(數據中都指定了消息類型的)調用相應的處理函數,消息類型和處理函數定義如下:
例如,如果收到invoke消息,就調用ubusd_handle_invoke()函數處理。
這些處理函數可能是ubusd處理完後需要回發給client數據,或者是將消息轉發給另一個client(如果發送請求的client需要和另一個client進行通信)。
3.處理完成後,向client發送處理結果,例如UBUS_STATUS_OK。(注意,client發送數據是UBUS_MSG_DATA類型的)
4.2 client的工作流程
ubus call obj method的工作流程:
1.創建一個unix socket(UDP)連接ubusd,並接收到server發過來的HELLO消息。2. ubus call命令由ubus_cli_call()函數進行處理,先向ubusd發送lookup消息請求obj的id。然後向ubusd發送invoke消息來調用obj的method方法。
3.創建epoll_fd並將client的fd添加到監聽列表中等待消息。
4. client收到消息後的處理函數為ubus_handle_data(),其中UBUS_MSG_DATA類型的數據receive_call_result_data()函數協助解析。
被call的client的工作流程:
和ubus客戶端的流程相似,只是變成了接受請求並調用處理函數



