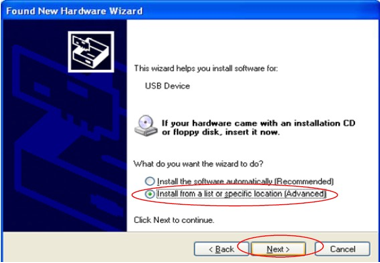
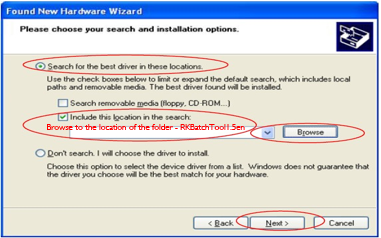
IEEE Std 802.1D and IEEE Std 802.1Q Reserved Addresses
Group MAC address value
|
Organization
using the value |
Standard using the value
|
Notes
|
01-80-C2-00-00-00
|
IEEE 802
|
IEEE Std 802.1D
IEEE Std 802.1Q |
IEEE Std 802.1D Bridge Group Address
|
01-80-C2-00-00-01
|
IEEE 802
|
"
|
IEEE MAC-specific control protocols
|
01-80-C2-00-00-02
|
IEEE 802
|
"
|
IEEE Std 802.3 Slow Protocols multicast address
|
01-80-C2-00-00-03
|
IEEE 802
|
"
|
IEEE Std 802.1X PAE address
|
01-80-C2-00-00-04
|
IEEE 802
|
"
|
IEEE MAC-specific control protocols
|
01-80-C2-00-00-05
|
IEEE 802
|
"
|
Reserved for media access method specific use
|
01-80-C2-00-00-06
|
IEEE 802
|
"
|
Reserved for future standardization
|
01-80-C2-00-00-07
|
IEEE 802
|
"
|
Reserved for future standardization
|
01-80-C2-00-00-08
|
IEEE 802
|
"
|
Provider Bridge group address
|
01-80-C2-00-00-09
|
IEEE 802
|
"
|
Reserved for future standardization
|
01-80-C2-00-00-0A
|
IEEE 802
|
"
|
Reserved for future standardization
|
01-80-C2-00-00-0B
|
IEEE 802
|
"
|
Reserved for future standardization
|
01-80-C2-00-00-0C
|
IEEE 802
|
"
|
Reserved for future standardization
|
01-80-C2-00-00-0D
|
IEEE 802
|
"
|
Provider Bridge MVRP address
|
01-80-C2-00-00-0E
|
IEEE 802
|
"
|
Std 802.1AB Link Layer Discovery Protocol address
|
01-80-C2-00-00-0F
|
IEEE 802
|
"
|
Reserved for future standardization
|
Standard Group MAC Addresses
Group MAC address value
|
Organization
using the value |
Standard using the value
|
Notes
|
01-80-C2-00-00-10
|
IEEE 802
|
IEEE Std 802.1D
|
All LANs Bridge Management Group Address (deprectated)
|
01-80-C2-00-00-11
|
IEEE 802
|
IEEE Std 802.1E
|
Load Server Generic Address
|
01-80-C2-00-00-12
|
IEEE 802
|
IEEE Std 802.1E
|
Loadable Device Generic Address
|
01-80-C2-00-00-13
|
unassigned
| ||
01-80-C2-00-00-14
|
ISO/IEC JTC1/SC6
|
ISO/IEC 10589
|
All Level 1 Intermediate Systems Address
|
01-80-C2-00-00-15
|
ISO/IEC JTC1/SC6
|
ISO/IEC 10589
|
All Level 2 Intermediate Systems Address
|
01-80-C2-00-00-16
|
ISO/IEC JTC1/SC6
|
ISO/IEC 10030
|
All CONS End Systems Address
|
01-80-C2-00-00-17
|
ISO/IEC JTC1/SC6
|
ISO/IEC 10030
|
All CONS SNARES Address
|
01-80-C2-00-00-18
|
IEEE 802
|
IEEE Std 802.1B
|
Generic Address for All Manager Stations
|
01-80-C2-00-00-19
|
unassigned
| ||
01-80-C2-00-00-1A
|
IEEE 802
|
IEEE Std 802.1B
|
Generic Address for All Agent Stations
|
01-80-C2-00-00-1B
|
ISO/IEC JTC1/SC6
|
ISO/IEC 9542
|
All Multicast Capable End Systems Address
|
01-80-C2-00-00-1C
|
ISO/IEC JTC1/SC6
|
ISO/IEC 9542
|
All Multicast Announcements Address
|
01-80-C2-00-00-1D
|
ISO/IEC JTC1/SC6
|
ISO/IEC 9542
|
All Multicast Capable Intermediate Systems Address
|
01-80-C2-00-00-1E
|
ISO/IEC JTC1/SC6
|
ISO/IEC 8802-5
|
All DTR Concentrators MAC Group Address
|
01-80-C2-00-00-1F
|
unassigned
| ||
01-80-C2-00-00-20 —
01-80-C2-00-00-2F |
IEEE 802
|
IEEE Std 802.1Q
|
Reserved for use by Multiple Registration Protocol (MRP) applications
|
01-80-C2-00-00-30 —
01-80-C2-00-00-3F |
IEEE 802
|
IEEE Std 802.1ag
|
Destination group MAC addresses for CCM and Linktrace messages
|
01-80-C2-00-00-40 to 01-80-C2-00-00-4F
|
IETF
|
TRILL
|
Group MAC addresses used by the TRILL protocols
|
01-80-C2-00-00-40 —
01-80-C2-00-00-FF |
unassigned
| ||
01-80-C2-00-01-00
|
ISO/IEC 9314-6
|
Ring Management Directed Beacon Multicast Address
| |
01-80-C2-00-01-01 —
01-80-C2-00-01-0F |
ISO/IEC JTC1/SC25
|
Assigned to ISO/IEC JTC1/SC25 for future use
| |
01-80-C2-00-01-10
|
ISO/IEC JTC1/SC25
|
ISO/IEC 9314-6
|
Status Report Frame Status Report Protocol Multicast Address
|
01-80-C2-00-01-11 —
01-80-C2-00-01-1F |
ISO/IEC JTC1/SC25
|
Assigned to ISO/IEC JTC1/SC25 for future use
| |
01-80-C2-00-01-20
|
ISO/IEC JTC1/SC25
|
ISO/IEC 9314-2
|
All FDDI Concentrator MACs
|
01-80-C2-00-01-21 —
01-80-C2-00-01-2F |
ISO/IEC JTC1/SC25
|
Assigned to ISO/IEC JTC1/SC25 for future use
| |
01-80-C2-00-01-30
|
ISO/IEC JTC1/SC25
|
ISO/IEC 9314-6
|
Synchronous Bandwidth Allocation Address
|
01-80-C2-00-01-31 —
01-80-C2-00-01-FF |
ISO/IEC JTC1/SC25
|
Assigned to ISO/IEC JTC1/SC25 for future use
| |
01-80-C2-00-02-00 —
01-80-C2-00-02-FF |
ETSI
|
Assigned to ETSI for future use
| |
01-80-C2-00-03-00 —
01-80-C2-FF-FF-FF |
unassigned
|
Group MAC Addresses Used in ISO 9542 ES-IS Protocol
Group MAC address value
|
Organization
using the value |
Standard using the value
|
Notes
|
09-00-2B-00-00-04
|
ISO/IEC JTC1/SC6
|
ISO 9542
|
All End System Network Entities Address
|
09-00-2B-00-00-05
|
ISO/IEC JTC1/SC6
|
ISO 9542
|
All Intermediate System Network Entities Address
|
Locally Administered Group MAC Addresses Used by IEEE Std 802.5
(IEEE Std 802.5 Functional Addresses)
(IEEE Std 802.5 Functional Addresses)
Group MAC address value
|
Organization
using the value |
Standard using the value
|
Notes
|
03-00-00-00-00-08
|
IEEE 802
|
IEEE Std 802.5
|
Configuration Report Server (CRS) MAC Group Address
|
03-00-00-00-00-10
|
IEEE 802
|
IEEE Std 802.5
|
Ring Error Monitor (REM) MAC Group Address
|
03-00-00-00-00-40
|
IEEE 802
|
IEEE Std 802.5
|
Ring Parameter Server (RPS) MAC Group Address
|
03-00-00-00-01-00
|
IEEE 802
|
ISO 9542
|
All Intermediate System Network Entities Address
|
03-00-00-00-02-00
|
ISO/IEC JTC1/SC6,
IEEE 802 |
ISO 9542, and
IEEE Std 802.5 |
All End System Network Entities Address, and Lobe Media Test (LMT) MAC Group Address
|
03-00-00-00-04-00
|
IEEE 802
|
IEEE Std 802.1B
|
Generic Address for all Manager Stations
|
03-00-00-00-08-00
|
IEEE 802
|
ISO/IEC 10030
|
All CONs SNARES Address
|
03-00-00-00-10-00
|
IEEE 802
|
ISO/IEC 10030
|
All CONs End System Address
|
03-00-00-00-20-00
|
IEEE 802
|
IEEE Std 802.1E
|
Loadable Device Generic Address
|
03-00-00-00-40-00
|
IEEE 802
|
IEEE Std 802.1E
|
Load Server Generic Address
|
03-00-00-40-00-00
|
IEEE 802
|
IEEE Std 802.1B
|
Generic Address for all Agent Stations
|